
Can LLMs predict human behavior?
Evidence from two studies.

As something of a counterpoint to my previous pieces, this post reviews two recent papers that use LLMs to simulate human survey responses. The punchline: they seem to do pretty well.
Using AI to predict how humans respond to experiments
Researchers often conduct large-scale survey experiments to measure things like how people form beliefs, react to political messaging, or evaluate policy proposals. Running these experiments on thousands of representative participants gets expensve quickly. What if researchers could use AI as their personal focus group to determine the best hypotheses to test in the field? If so, it could help researchers prioritize the most promising research ideas, determine needed sample sizes, and efficiently apply their resources to produce the most useful results.
Hewitt et al. (2024) put an LLM to the test on an archive of 70 nationally-representative survey experiments in the US. They prompted GPT-4 to simulate how Americans would respond to each experimental treatment in the archive.
Consider this paper by Elizabeth C. Connors that appears in the data. The study includes an experiment in which a nationally-representative group of participants is asked to give feeling thermometer scores from 0 to 100 for how they feel about Democrats and Republicans, where 0 to 50 indicates negative feelings and 50 to 100 indicates positive feelings. The difference in scores for the respondent’s own party and the opposing party is a measure of political polarization. Connors asks respondents the following:
Please answer the following [feeling thermometer questions] as you think a [Republican/Democrat] wanting to [impress/disappoint] other [Republicans/Democrats] would.
Respondents were only asked to think from the perspective of their own self-reported party, but the experiment randomized whether they should respond with the intention of impressing or disappointing their co-partisans. Connors (2024) find a 106 point change in the polarization measure when respondents are asked to impress rather than disappoint members of their own party (a huge effect!).
Hewitt et al. (2024) ask whether the LLM can indeed predict that the treatment would lead to a 106 point change. They conduct this same exercise for all 70 studies in the archive, spanning 476 experimental treatments. They find that the LLM is impressively accurate at predicting treatment effects (r=0.85), including on unpublished studies that could not appear in the LLM’s training data (r=0.90). The LLM predicts these effects comparably well to human experts asked to give forecasts of likely effect sizes.
The AI's predictive powers were particularly strong for text-based interventions with survey-based outcomes—suggesting promising applications in political polling and market research. However, its performance was not quite as strong on real-world field experiments where the model’s text-based training data may offer less insight into human behavior.
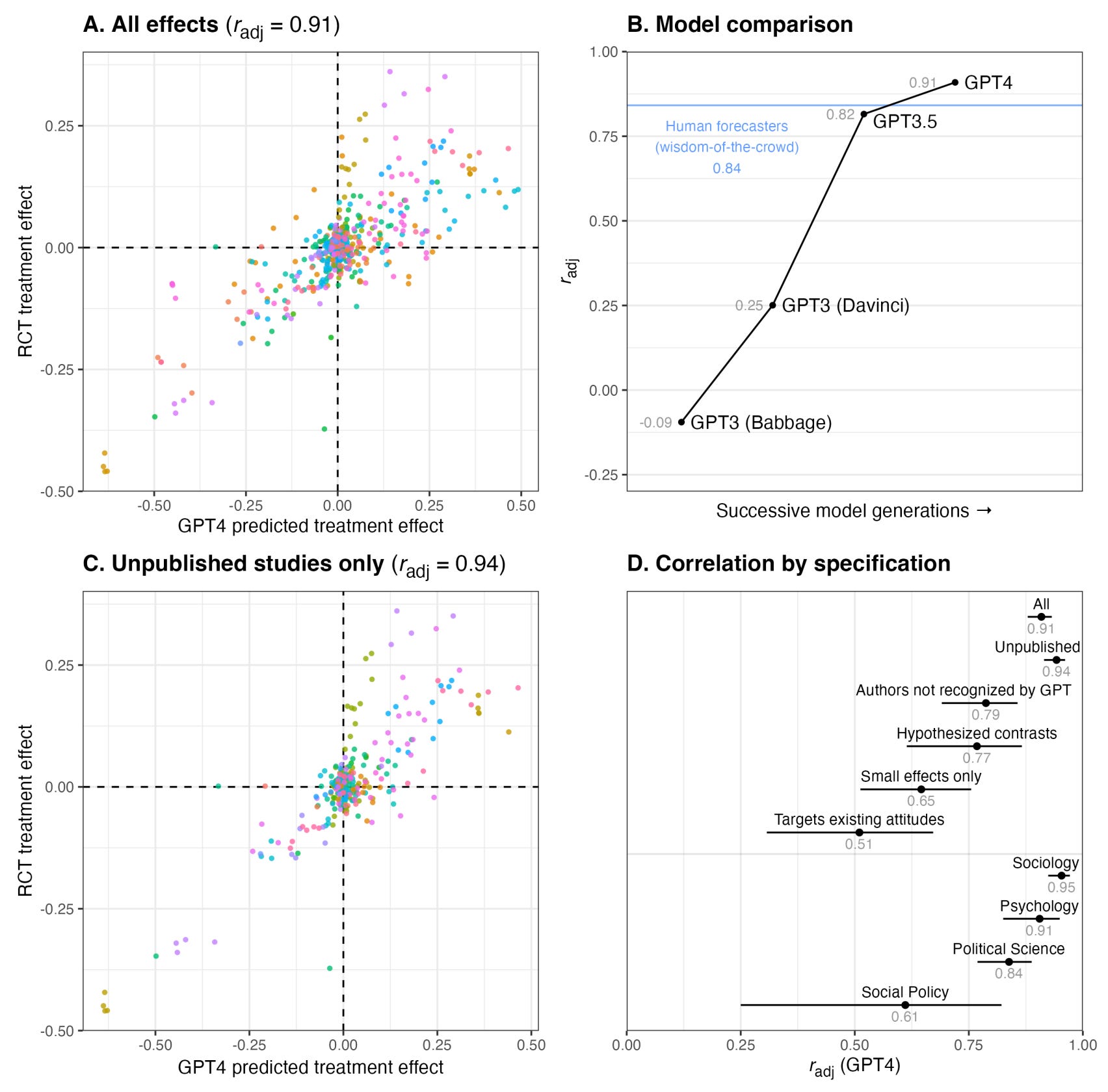
Overall, Hewitt et al. (2024) shows that LLMs are quite good at anticipating how humans react to intricate behavioral experiments spanning psychology, public health, sociology, political science, and economics.
An AI simulation of you
Park et al. (2024) is another remarkable study in this space. Can an AI know you so well that it can predict your political opinions, religious beliefs, and social attitudes?
To study this, the authors first conduct two-hour long qualitative interviews with over 1000 people. They then build a simulated agent for each person by feeding their interview transcripts into an LLM. Each participant and their digital twin then completes a battery of surveys and behavioral tasks. The authors compare how well the AI replicates the human’s responses on the surveys.
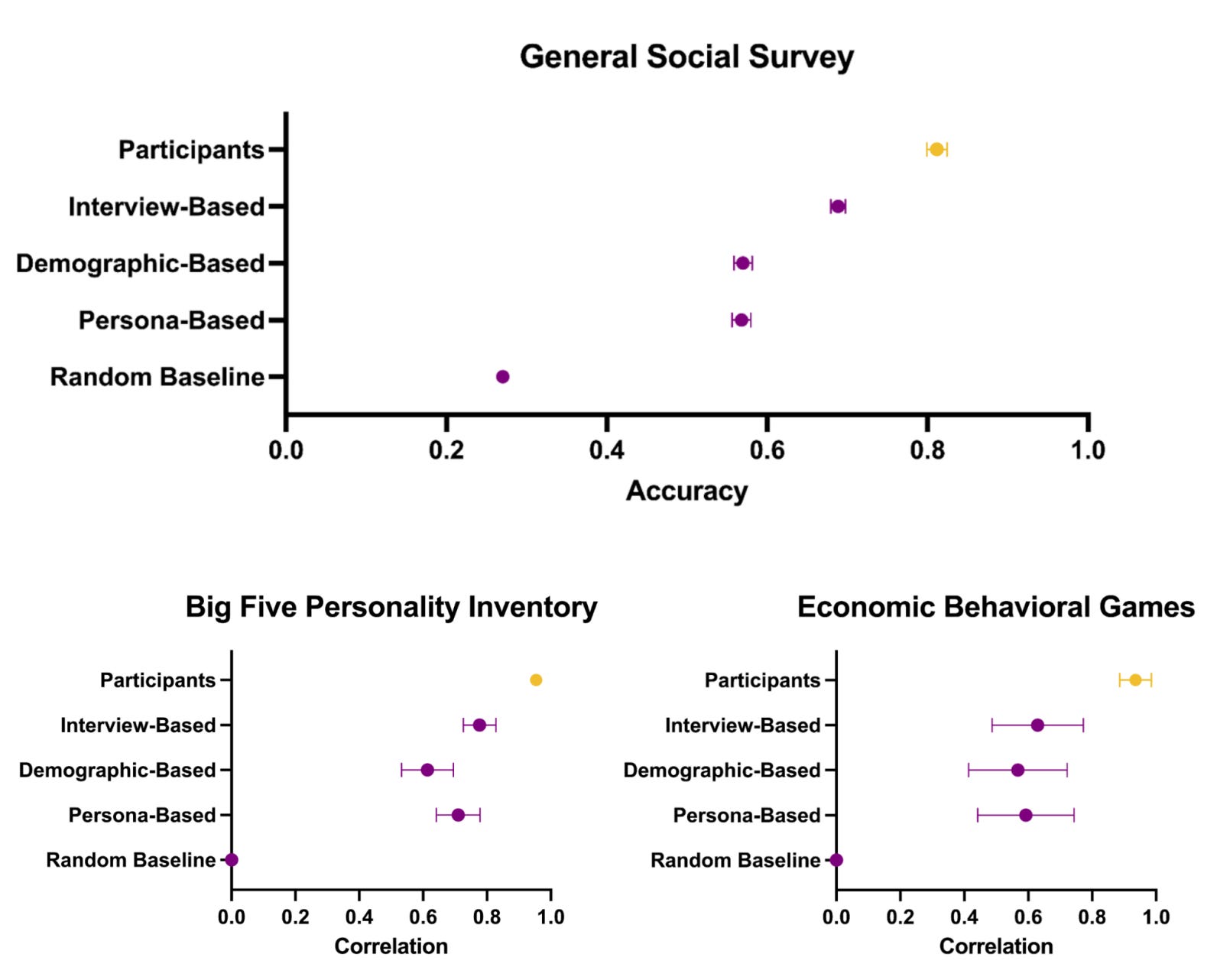
Consider responses to the General Social Survey (GSS), one of the most influential studies in the social sciences. The survey queries respondents' opinions on matters ranging from government spending to the state of race relations to the existence and nature of God. The simulated agent predicts responses to the GSS with 69% accuracy. To put this in perspective, when humans retook the same survey two weeks later, only 81% of their answers matched their original responses. This gives the AI a normalized accuracy score of 0.85.
How valuable are the two-hour interviews for improving accuracy? The authors evaluate this using two points of comparison. The first compares responses from LLM agents fed only demographic information about the participant, such as their age, gender, race, and political ideology (forming a “demographic-based agent”). The second generates predictions from agents given one brief paragraph that participants write about their own personal background and personality (“persona-based agents”). The demographic-based agents have a normalized accuracy of 0.71, while the persona-based agetns have a score of 0.70.
The simulated agent seems fairly accurate at predicting GSS responses. Further, conducting a two-hour interview seems to lead to a meaningful improvement relative to simpler approaches such as providing demographic information. Results seem somewhat less impressive for predicting Big Five personality traits or decisions in economic behavioral games such as the dictator game. For these components the simulated agents given the full interview transcripts performed more comparably to the demographic-based and persona-based agents, with overall accuracy scores also lower.
Takeaways
LLMs can model certain aspects of human behavior with meaningful accuracy, particularly in experimental contexts with text-based stimuli.
Overall, the results in Hewitt et al. (2024) seem more impressive than the results in Park et al. (2024).
This is in part because Hewitt et al. (2024)’s comparison to human forecasts is a more natural benchmark. What would be a good threshold for accuracy in the Park et al. study?
Park et al. (2024) tries to solve a more difficult problem for LLMs.
Treatment effects in experiments are averages across lots of people. It seems plausible that the a model trained on a huge corpus of text might be able to form a good guess at these averages, as borne out in Hewitt et al. (2024).
Guessing individual responses to surveys or behavioral games requires a highly accurate model of individual personality characteristics, not just average characteristics. Two hours of interviews may not be enough to form a perfect model of a person’s personality and values.
We should think of these results as lower bounds on AI capabilities. Replicating these studies today (only a few months later!) would likely lead to more impressive results given the rapid improvement in foundation models.